Архитектура, устройство и функционирование вычислительных систем / Лаба 9 / отчет архитект_9
.docxЛабораторное занятие №9
Цель работы: знакомство с процессом кластеризации данных с помощью самоорганизующихся карт признаков. Определение структуры карты и параметров обучения, оценка эффективности кластеризации, содержательная интерпретация кластеров.
Задание:
показать структуру кластеров карты Кохонена;
составить таблица, полученная при содержательной интерпретации кластеров.
Ход работы

Структура сети Кохонена
Каждый выходной нейрон ассоциирован с кластером и, следовательно, в зависимости от того, какой из нейронов возбуждается при подаче на вход НСК определенного наблюдения, оно относится к соответствующему кластеру.
Обучение сетей Кохонена. Для обучения НСК используется конкурентное обучение или алгоритм Кохонена - итеративная процедура, в которой нейроны выходного слоя «конкурируют» между собой за право оказаться «ближе» к векторам обучающих примеров, подаваемых на вход сети. В начале обучения веса нейронов инициализируются небольшими случайными значениями. Каждая итерация содержит следующие шаги:
1.
Конкуренция(competition).
На вход сети поступает обучающий пример
![]() и
для него определяется выходной нейрон,
вектор весов которого наиболее близок
к
и
для него определяется выходной нейрон,
вектор весов которого наиболее близок
к
![]() .
Такой нейрон объявляется «победителем».
.
Такой нейрон объявляется «победителем».
2.
Объединение(cooperation).
Для нейрона-победителя определяется
группа нейронов вы-ходного слоя,
расстояние до которых не превышает
заданной величины, называемой радиусом
обучения
![]() .
Все нейроны, оказавшиеся в пределах
радиуса обучения нейрона-победителя,
должны подстраивать свои веса в
направлении его вектора. В результате
нейрон-победитель становится центром
некоторого соседства нейронов с близкими
векторами весов.
.
Все нейроны, оказавшиеся в пределах
радиуса обучения нейрона-победителя,
должны подстраивать свои веса в
направлении его вектора. В результате
нейрон-победитель становится центром
некоторого соседства нейронов с близкими
векторами весов.
3.
Подстройка
(adaptation).
Выполняется подстройка весов нейронов,
оказавшихся в пределах радиуса обучения
нейрона-победителя. Пусть на вход сети
Кохонена поступает
![]() -й
пример, случайно выбираемый из обучающего
множества
-й
пример, случайно выбираемый из обучающего
множества
![]() .
.
Данные для анализа:
E |
nca |
ca |
eq |
ltd |
stl |
rfs |
cp |
np |
E1 |
5116652 |
1655737 |
4912417 |
619623 |
1240349 |
6391468 |
5820259 |
532581 |
E2 |
1226241 |
1224983 |
1457028 |
93921 |
900275 |
5027062 |
3462529 |
499271 |
E3 |
5851307 |
1460596 |
421161 |
395121 |
1295621 |
4489673 |
2291589 |
67368 |
E4 |
86188 |
840198 |
93900 |
604792 |
227694 |
141282 |
122932 |
10 |
E5 |
213652 |
289893 |
187876 |
138430 |
177239 |
474607 |
439172 |
8238 |
E6 |
292249 |
410349 |
44432 |
14565 |
643601 |
684336 |
636529 |
-36067 |
E7 |
107355 |
265899 |
132056 |
7656 |
233542 |
293423 |
302575 |
110 |
E8 |
155221 |
797983 |
74255 |
860 |
878949 |
244337 |
249286 |
-133140 |
E9 |
2852 |
69444 |
-27284 |
913 |
98667 |
173460 |
126278 |
-27697 |
E10 |
292001 |
130363 |
129216 |
155051 |
138097 |
357466 |
312348 |
-5967 |
E11 |
659633 |
1295344 |
132248 |
1650653 |
1172076 |
1671660 |
1626270 |
122137 |
E12 |
170298 |
666081 |
616076 |
582 |
219721 |
1002735 |
807602 |
117997 |
1. Запустили аналитическую платформу Deductor и загрузили обучающий набор данных нажав на кнопку Мастер импорта.
2. Открыли окно Мастера обработки и на 1-м шаге в секции Data Mining выбрали пункт «Самоорганизующаяся карта Кохонена».
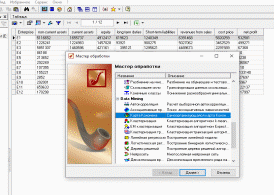
На 2-м шаге указали столбцу "Предприятие" (Enterprise) назначение "Информационное", а остальным столбцам – "Входное".
На 3-м шаге Мастера обработки отключили использование тестового множества.
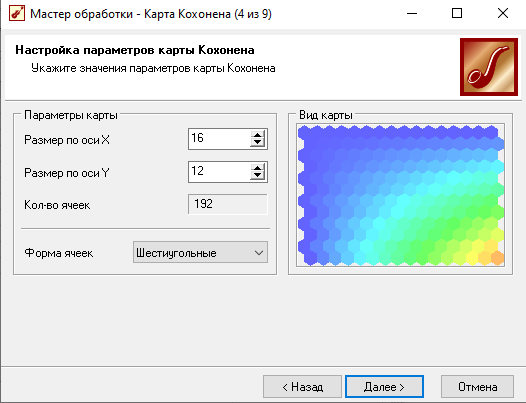
На 4-м шаге установили параметры карты: размер по X– 16 ячеек, поY– 12 ячеек, форма ячеек – 6 угольная.
На 5-м шаге, параметры остановки обучения, настройки оставили по умолчанию.
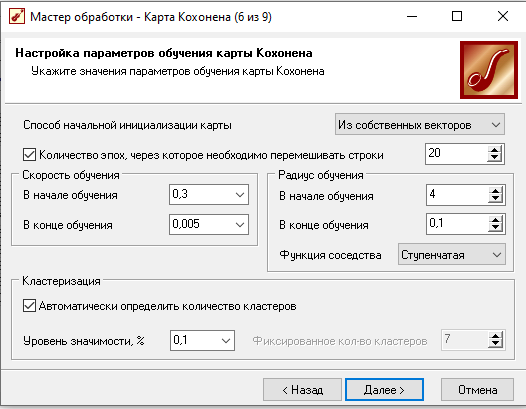
На 6-м шаге установили параметры обучения карты следующим образом:
- способ начальной инициализации весов карты – случайными значениями;
- количество эпох, через которое необходимо перемешивать строки - 20;
- скорость обучения: в начале обучения 0,3, в конце обучения 0,05;
- радиус обучения: в начале обучения 4, в конце обучения 0,1;
- функция соседства ступенчатая.
- число кластеров выбрать соответствующим числу ожидаемых групп объектов со сходными свойствами в обучающем наборе данных, если имеются некоторые априорные сведения.
- уровень значимость выбрали 0,1.
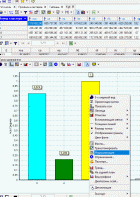
Для отображения полученных групп кластеров выбрали в обработчике "Кластеризация" из списка визуализаторов способы отображения данных: "Что-если" для решения задачи классификации, отнесение нового предприятия к одному из кластеров, "Профили кластеров" для определения структуры формирования группы кластеров и "Куб" для наглядного просмотра полученных результатов.
Для настройки визуализатора "Куб" выбрали рассматриваемые свойства как факты, а номер кластера как измерение.
В "Профили кластеров" представлены все рассматриваемые свойства вместе с характером влияния их на состав кластера.
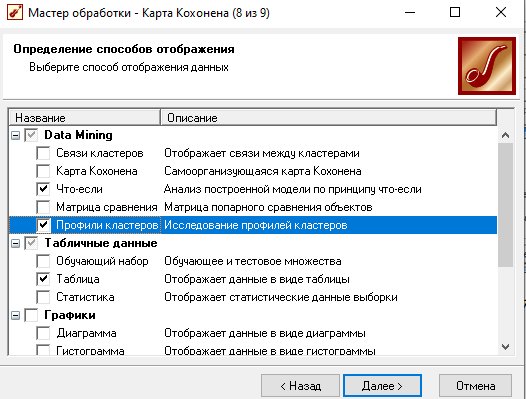
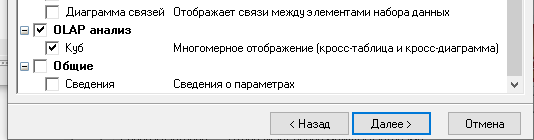
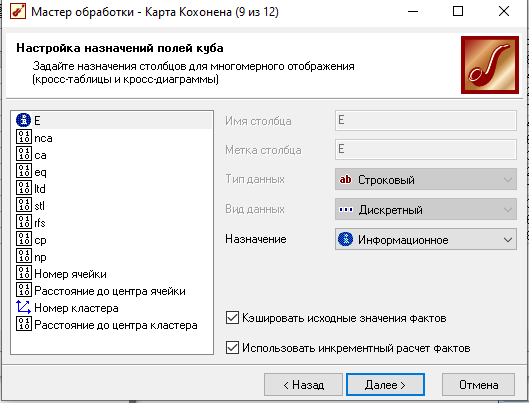
Далее определили, как в таблице располагать измерения и факты
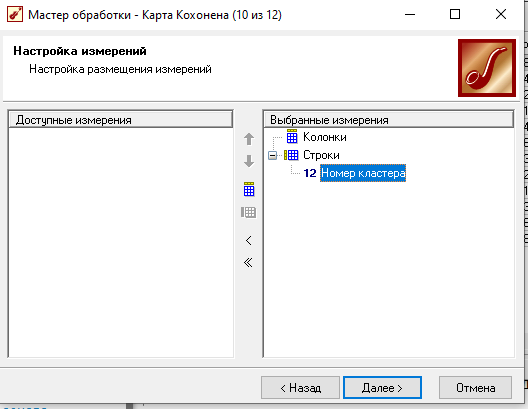
Для каждого факта выбрали вычисление среднего по рассматриваемой группе.
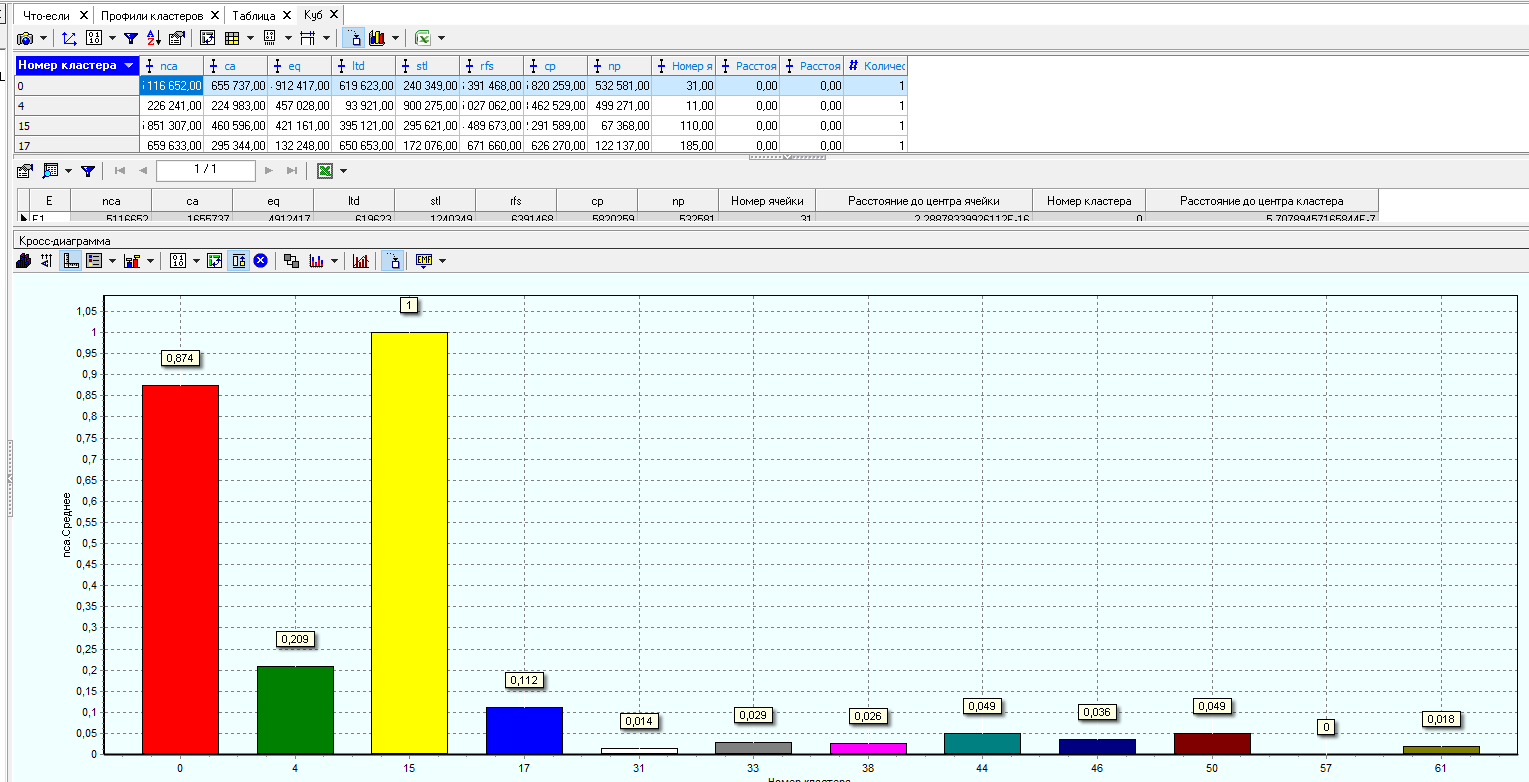
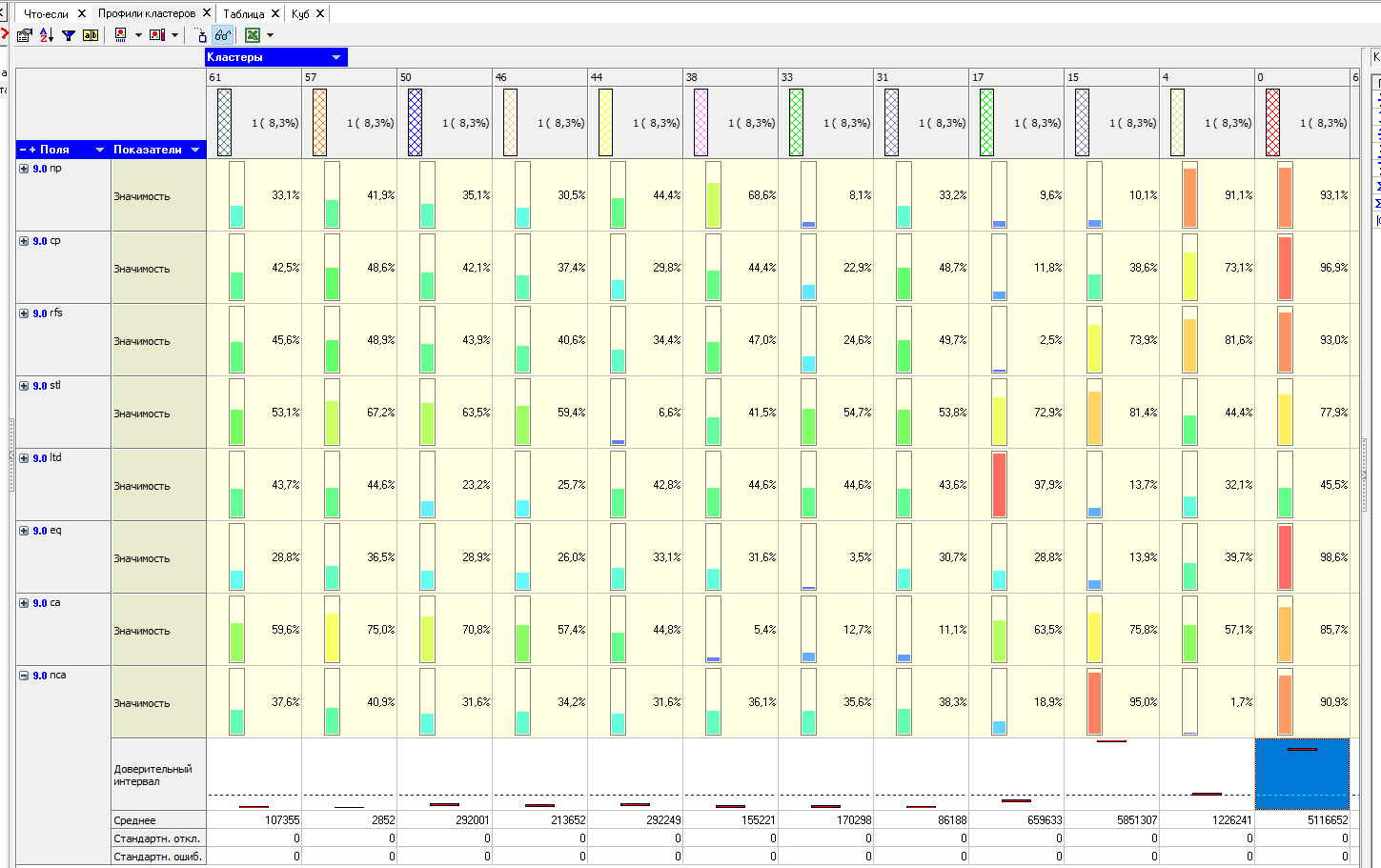
Алгоритм автоматически разбил предприятия на два кластера с разной поддержкой и разными процентами значимости свойств. Первый кластер содержит 8 предприятий, второй – 4.
Самым значимым для первого кластера является «Выручка от реализации», для второго «Оборотные активы».
При построении кросс-диаграммы на панели инструментов окна кросс-диаграммы нажали кнопки «Нормализация, приведение графиков к единому масштабу».
Добавили в кросс-диаграмму все параметры, по которым проводилась кластеризация, и легенду, которая укажет каким цветом какой параметр отображается.